








本文将介绍 22 种先进的RAG技术,灵感来源于 all-rag-techniques 仓库中的全面实现。这些实现使用 Python 库(如 NumPy、Matplotlib 和 OpenAI 的嵌入模型),避免使用 LangChain 或 FAISS 等依赖,以保持简单性和清晰度。
本文目录:

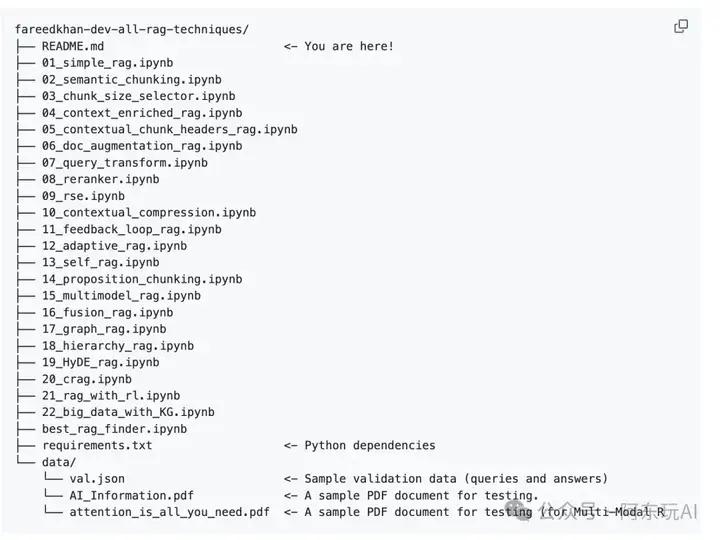
代码目录
1. 简单 RAG
简单 RAG 是一个基础的RAG实现,为初学者提供了一个快速上手的起点。它包括以下核心步骤:
- 文档分割:将输入文档分割成固定大小的文本块。
- 嵌入生成:使用预训练模型(如 OpenAI 的嵌入模型)为每个文本块生成向量表示。
- 检索:将用户查询嵌入到向量空间中,通过余弦相似度检索与查询最相关的文本块。
- 生成:将检索到的文本块与查询一起输入到语言模型中中,生成最终答案。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/01_simple_rag.ipynb
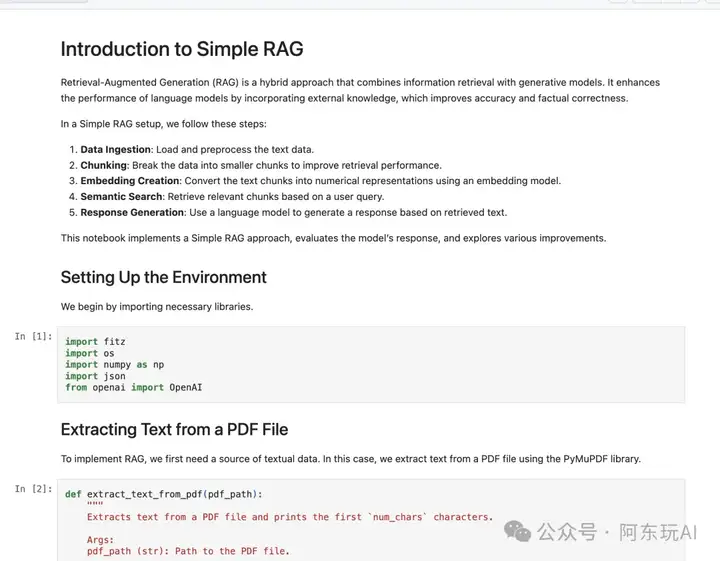
应用场景:快速原型设计、简单问答系统、基础知识检索。
2. 语义分块
语义分块 通过基于语义的相似性分割文本,生成更有意义的片段。相比固定大小的分块,语义分块使用嵌入模型评估相邻句子的语义相似度,将语义相关的句子合并为一个片段。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/02_semantic_chunking.ipynb
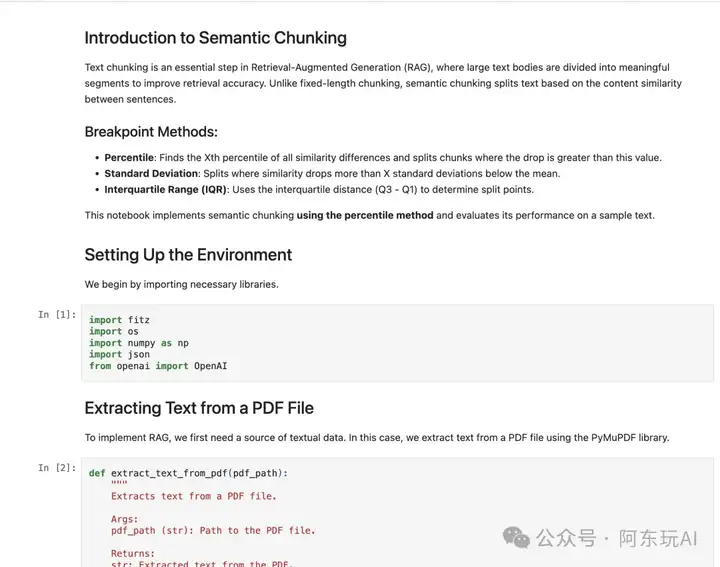
应用场景:需要高质量上下文的任务,如法律文档分析或学术论文检索。
3. 分块大小选择器
分块大小选择器 研究不同的分块大小(如 256、512、1024 个字符)对检索性能的影响。它通过实验比较不同分块大小下的召回率和生成质量,帮助用户找到最佳分块策略。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/03_chunk_size_selector.ipynb
应用场景:优化RAG系统以适应不同文档类型,如短新闻或长篇技术报告。
4. 上下文增强 RAG增强
上下文增强 RAG 通过检索与目标分块相邻的文本片段,为生成提供更多上下文信息。这可以避免因分块分割导致的上下文信息,提升答案的连贯性和准确性。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/04_context_enriched_rag.ipynb
应用场景:需要完整上下文的任务,如长篇叙事性文档或技术手册问答。
5. 上下文分块标题
上下文分块标题 在嵌入每个分块之前,为其添加描述性标题。这些标题由语言模型生成,总结分块内容,增强嵌入的语义表达能力。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/05_contextual_chunk_headers_rag.ipynb

应用场景:复杂文档的检索,如多章节书籍或多主题报告。
6. 文档增强 RAG
文档增强 RAG 从文本分块中生成问题,并将这些问题作为额外的查询嵌入向量库,增强检索过程的语义覆盖范围。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/06_doc_augmentation_rag.ipynb

应用场景:需要深入挖掘文档内容的任务,如教育问答或知识库查询。
7. 查询转换
查询转换 通过重写、扩展或分解用户查询来改善检索效果。它包括:
- 回溯提示:生成更广义的查询以捕捉更广泛的上下文。
- 子查询分解:将复杂查询拆分为多个简单子查询,分别检索。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/07_query_transform.ipynb
应用场景:复杂查询处理,如多方面问题或模糊用户意图。
8. 重排器
重排器 使用大型语言模型(LLM)对初步检索结果重新排序,根据查询的相关性对结果进行优化。它通过评估每个分块与查询的语义匹配度,显著提高检索精度。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/08_reranker.ipynb
应用场景:高精度检索任务,如医疗诊断支持或法律案例分析。
9. 相关段落提取(RSE)
相关段落提取(RSE) 识别并重构连续的文本段落,保留完整的上下文信息。它通过分析检索到的分块,合并相邻或语义相关的片段,形成更连贯的上下文。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/09_rse.ipynb

应用场景:需要完整段落的任务,如文献综述或故事性内容生成。
10. 上下文压缩
上下文压缩 过滤并压缩检索到的分块,仅保留与查询高度相关的信息,减少冗余内容,优化生成效率。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/10_contextual_compression.ipynb
应用场景:实时问答系统或资源受限环境。
11. 反馈循环 RAG
反馈循环 RAG 结合用户反馈(如答案评分或更正),通过持续学习改进检索和生成过程。它使用反馈数据微调嵌入模型或调整检索策略。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/11_feedback_loop_rag.ipynb

应用场景:长期运行的交互系统,如客户支持聊天机器人。
12. 自适应 RAG
自适应 RAG 根据查询类型(如事实性、概念性或探索性)动态选择最佳检索策略。例如,事实性查询可能优先精确匹配,而概念性查询需要更广泛的语义检索。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/12_adaptive_rag.ipynb

应用场景:多场景问答系统,如企业知识库或教育平台。
13. 自我 RAG
自我 RAG 动态决定是否需要检索、如何检索,并评估检索结果的相关性和答案的支持度。它通过自省机制优化整个RAG流程。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/13_self_rag.ipynb
应用场景:高自主性任务,如智能助手或自动化研究工具。
14. 命题分块
命题分块 将文档分解为原子性的事实陈述(如“地球是圆的”),每个陈述独立嵌入以实现精确检索。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/14_proposition_chunking.ipynb
应用场景:需要高精度事实提取的任务,如知识图谱构建或验证系统。
15. 多模态RAG
多模态RAG 结合文本和图像进行检索,使用 LLaVA 等模型为图像生成描述性标题,并将其嵌入向量空间与文本共同检索。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/15_multimodel_rag.ipynb
应用场景:多媒体内容检索,如电商产品搜索或教育资源库。
16. 融合RAG
融合 RAG 结合向量搜索(语义)与基于关键词的 BM25 检索,综合两者的优势以提高检索效果。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/16_fusion_rag.ipynb
应用场景:混合搜索场景,如学术搜索或企业文档管理。
17. 图谱 RAG
图谱 RAG 将知识组织为图结构,节点表示概念,边表示关系,支持通过图遍历检索相关信息。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/17_graph_rag.ipynb
应用场景:复杂知识网络,如生物医学研究或法律案例分析。
18. 层次 RAG
层次 RAG 构建层次索引,包含高层次摘要和详细分块,支持从粗到细的检索策略。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/18_hierarchy_rag.ipynb
应用场景:大规模文档检索,如技术文档库或法规数据库。
19. HyDE RAG
HyDE RAG 使用假设性文档嵌入(Hypothetical Document Embeddings),生成与查询相关的虚拟文档嵌入,改善语义匹配。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/19_HyDE_rag.ipynb
应用场景:语义模糊查询,如探索性研究或创意写作支持。
20. 纠正性 RAG(CRAG)
纠正性 RAG 动态评估检索结果的质量,若结果不佳则使用网络搜索作为后备,确保答案的准确性。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/20_crag.ipynb

应用场景:需要高可靠性答案的场景,如实时新闻问答或医疗咨询。
21. 带强化学习的RAG
带强化学习的RAG 使用强化学习优化RAG模型,通过最大化奖励(如答案准确性或用户满意度)提升性能。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/21_rag_with_rl.ipynb
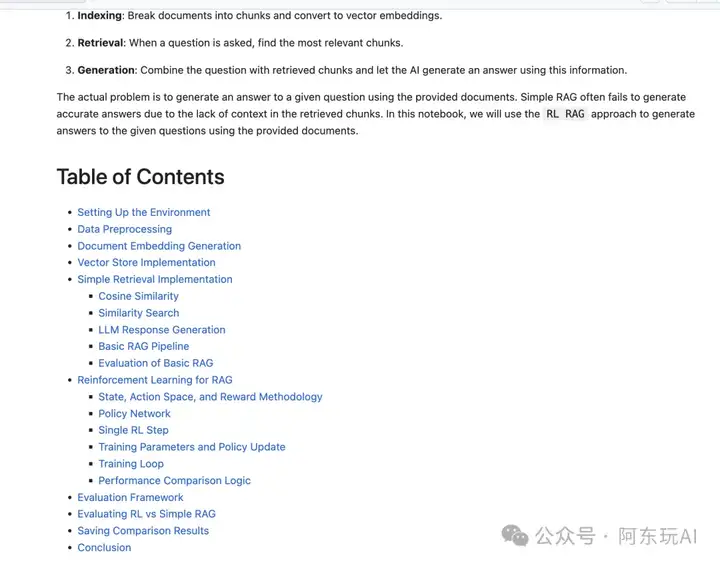
应用场景:需要长期优化的系统,如个性化推荐或智能问答。
22. 大数据知识图谱RAG
大数据知识图谱 RAG 专为大规模数据集设计,使用知识图谱组织海量信息,支持高效检索和复杂查询。
地址:https://github.com/FareedKhan-dev/all-rag-techniques/blob/main/22_Big_data_with_KG.ipynb

应用场景:大数据分析,如企业级知识管理或科学研究。
最佳RAG选择器
除了上述技术,all-rag-techniques 仓库还提供了一个 最佳RAG选择器,通过结合简单 RAG、重排器和查询重写,自动为给定查询选择最适合的RAG技术。这为开发者提供了一个灵活的工具,用于快速评估和部署最优RAG策略。
应用场景:快速实验和生产环境中的RAG技术选择。
总结
这些RAG技术展示了从基础到高级的多种实现方式,涵盖了不同的应用场景和优化目标。无论是需要高精度的事实检索、复杂上下文理解,还是多模态信息处理,all-rag-techniques 仓库都提供了清晰的实现参考。开发者可以根据任务需求选择合适的RAG技术,或组合多种技术以构建更强大的系统。
通过这些技术,RAG 不仅提升了生成模型的准确性和上下文相关性,还为知识密集型任务提供了灵活的解决方案。未来,随着嵌入模型和检索算法的进一步发展,RAG技术将继续在智能问答、知识管理和多模态应用中发挥重要作用。
{
“target”:”简单认识我”,
“selfInfo”:{
“genInfo”:”大厂面试官,中科院硕士,从事数据闭环业务、RAG、Agent等,承担技术+平台的偏综合性角色。善于调研、总结和规划,善于统筹和协同,喜欢技术,喜欢阅读新技术和产品的文章与论文”,
“contactInfo”:”abc061200x, v-adding disabled”,
“slogan”:”简单、高效、做正确的事”,
“extInfo”:”喜欢看电影、喜欢旅游、户外徒步、阅读和学习,不抽烟、不喝酒,无不良嗜好”
}
}
文章来自于“阿东玩AI”,作者“阿东”。









