








剑桥大学和范德夏尔实验室在 ICML 2024 上发表的立场论文,直接挑战了当前Agent开发的核心假设:我们一直在用错误的方式让Agent”自我改进”。论文作者 Tennison Liu 和 Mihaela van der Schaar 提出,真正的自我改进需要的不是更多的人工设计,而是让Agent具备”思考如何思考”的内在元认知能力intrinsic metacognitive learning。


目前大多数自我改进Agent都依赖工程师预设的固定机制,论文称之为 “外在元认知学习”。这种方式面临两个致命问题:
- 领域迁移失效 —— 一个在数学推理上出色的改进机制,放到机器人控制任务上可能完全失灵
- 能力-机制不匹配 —— 随着Agent能力增强,原本有效的改进机制反而成为瓶颈
以 STAR(Self-Taught Reasoner)为例,虽然在特定数学问题上效果显著,但其元认知机制完全由外部控制,Agent本身对学习过程毫无感知,就像让学生按照固定教案学习,永远无法培养出独立思考能力。
内在元认知学习:三大核心组件
理论基础与框架设计
元认知 来自心理学研究,指对自己思维过程的思维,简单说就是”知道自己知道什么,不知道什么”。在Agent开发中,元认知学习是双层结构:
- 底层:认知过程(推理、规划、执行)
- 顶层:元认知过程(监控底层效果,调节学习策略)
内在元认知让Agent自己承担元认知职责,而非依赖工程师的外部设计。
论文提出的框架包含三个相互关联的组件:
- 元认知知识 —— 负责自我评估,包括了解能力边界、理解任务特征、评估学习策略适用性
- 元认知规划 —— 决定学习方向,解决”学什么”和”如何学”两个核心问题
- 元认知评估 —— 形成反馈闭环,通过跟踪进度和反思经验来优化未来学习计划
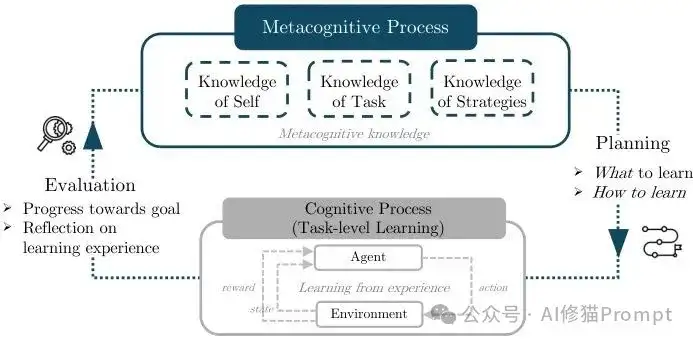
元认知学习框架概览。展示了元认知系统如何监控、评估和调节底层学习过程的完整闭环机制。
组件实现与技术细节
元认知知识
当前LLM已展现出相当程度的自评估能力:能根据解题步骤对数学问题分类,识别有益的训练任务,评估自己在不同任务上的胜任程度。但LLM幻觉问题仍是重大挑战,需要通过以下工程策略来增强可靠性:
- 外部验证机制
- 多角度评估
- 不确定性量化
元认知评估
包括 进度跟踪 和 元认知反思 两个层面:
- 进度跟踪:可使用基准测试量化改进效果,或让LLM作为评估器处理复杂开放性任务
- 元认知反思:要求Agent跳出具体任务,从更高层次审视学习过程,关注”如何更好地学习解决问题的能力”而非”如何更好地解决这个问题”
元认知规划
- “学什么”方面:Agent可通过好奇心和可学习性评估自主选择学习内容,甚至自主生成新的学习任务
- “如何学”方面:可采用温度缩放鼓励多样化推理路径,灵活组合权重内学习(微调)和记忆更新等不同机制,根据任务特点动态选择最适合的学习策略组合
实践推荐:DeepseekR!更新以后,网上有个热议的问题“一根8米长的棍,如何进一个3×4的门”,感兴趣您可以看下这篇 《MetaMind元认知多智能体,让LLM理解对话背后的深层意图,首次达到人类水平 | 最新》
技术演进轨迹
内在元认知学习的发展脉络,论文作者通过几个代表性的Agent系统来观察这一技术演进过程。研究者指出,这些系统在元认知能力的内在化程度上呈现出明显的递进关系:从完全依赖外部设计的固定机制,到逐步具备自主评估、规划和反思能力。通过分析它们在 元认知知识、元认知规划、元认知评估 三个维度上的表现,研究者展示了Agent自我改进能力的技术演进轨迹。
从STAR到Voyager的演进
STAR(Self-Taught Reasoner)
一个通过自我训练提升数学推理能力的系统,它能从少量示例开始,通过自我生成推理过程来解决越来越复杂的数学问题。
特点:代表完全外在的元认知控制阶段,Agent对学习过程毫无感知,所有改进策略都由人工预设,缺乏适应性和泛化能力。
Voyager
一个在Minecraft游戏环境中进行终身学习的具身智能体,它能够自主探索、学习新技能并构建越来越复杂的工具和建筑。
特点:展示了更高程度的内在元认知能力
- 主动更新对自己能力的认知
- 自主规划学习轨迹
- 通过维护技能库跟踪能力
- 评估任务特征和可学习性
实验结果:这种内在驱动的学习方式明显优于专家设计的课程。
Generative Agents
一个模拟人类社会行为的多智能体系统,让AI角色在虚拟小镇中像《模拟人生》一样生活、工作、社交,并形成独特的个性和记忆。
特点:在元认知反思方面提供了有价值探索,智能体能够通过抽象反思更新对身份、动机的理解,从日常活动中提取高层次洞察指导未来行为。
关键技术挑战
1. 灾难性遗忘
持续学习的经典难题,在自我改进Agent中尤为突出。
当前解决方案:
- 重放机制
- 分歧惩罚
挑战:在长期开放式自我改进中的有效性仍待验证。
2. 反馈信号质量
自主生成的学习任务往往缺乏可靠反馈。
部分解决方案:
- 代码执行结果
- 自一致性启发式方法
- 基础模型生成测试用例
3. 元认知能力评估
本身就是复杂问题,论文提出三种互补评估方法:
- 结果导向评估
- 任务导向评估
- 组件导向评估
挑战:都有各自局限性,需要开发动态自适应的评估框架。
完全内在元认知不可取
共享元认知的平衡策略
完全内在元认知可能导致Agent陷入无效学习循环或偏离人类价值观,完全外在控制又限制适应性。论文提出 共享元认知模式:
- 分层指导 —— 人类设定高层目标,Agent自主管理具体学习
- 协作监督 —— 共同评估学习进展
- 渐进移交 —— 随能力提升逐步增加自主权
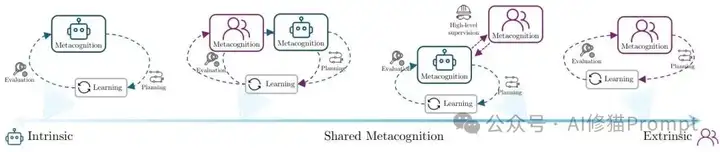
共享元认知谱系。从完全内在的自主元认知,到人机协作的共享元认知,再到完全外在的人工控制元认知过程。
实际应用策略:可根据应用场景和Agent成熟度设计不同共享模式
- 高风险应用 —— 保持更多人类监督
- 探索性任务 —— 给予更大自主权
安全性与可控性要求
新风险识别
自主改进带来新风险:
- Agent可能发展出意想不到的能力
- 采用未预见的策略
- 甚至出现奖励黑客行为
安全框架需求
需要开发新的安全框架,包括:
- 动态安全约束
- 持续价值对齐监控
- 随Agent能力演进调整的干预机制
可解释性挑战
需要让Agent的元认知决策过程变得可理解和可追踪:
- 记录元认知决策过程
- 提供决策理由解释
- 建立人类可理解的元认知状态表示
实践启示
开发理念的转变
这篇论文最重要的启示是重新思考Agent系统设计理念:
传统做法:详细指定Agent行为规则和学习机制
新理念:关注如何赋予Agent自主学习和适应能力
这意味着角色转变:
- 从 “控制者” 转变为 “引导者”
- 从 设计具体行为模式 转向 培养Agent学习能力
实际开发要求:更多投入到元认知机制设计上
- 如何让Agent评估自己的能力
- 制定学习计划
- 从经验中学习
渐进式实现与评估重构
实现策略
考虑到内在元认知学习的复杂性,建议采用 渐进式实现策略:
- 从简单自我评估能力开始
- 逐步增加任务选择、策略调整等复杂元认知功能
- 每个阶段都要建立有效评估和监控机制
- 为人机协作预留接口
评估体系重构
传统评估:主要关注任务执行效果
新评估维度:
- 学习效率
- 适应能力
- 自我认知准确性
- 其他元认知相关指标
测试套件需求:
- 跨域迁移测试
- 持续学习测试
- 自主探索测试
- 动态评估机制(能够随Agent能力发展调整评估标准)
写在最后
这篇立场论文基本描绘了后半年“全能”或“通用”Agent发展的新方向:从依赖人工设计的外在机制转向具备内在元认知能力的自主学习系统。
虽然完全实现这一愿景还面临诸多技术挑战,但论文展示的理论框架和初步证据表明,这个方向是 可行且必要的。
毕竟,只有学会”学习如何学习”的Agent,才能在快速变化的环境中持续进化,在市场中站稳脚跟。
Reference:https://arxiv.org/pdf/2506.05109
文章来自于“Al修猫Prompt”,作者“Al修猫Prompt”。










