








随着 GPT-4o 展现出令人印象深刻的多模态能力,将视觉理解和图像生成统一到单一模型中已成为 AI 领域的研究趋势(如MetaQuery 和 BLIP3-o )。
南洋理工大学 S-Lab 和商汤科技的研究团队推出 OpenUni,一个开源版 MetaQuery,仅用 1.1B 参数达到 8B 模型性能,更将代码、权重、数据全部开源!

- 技术报告: OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
- 机构: 南洋理工大学 S-Lab、商汤科技新加坡研究院
- 作者: Size Wu*, Zhonghua Wu*, Zerui Gong* (* 同等贡献), Qingyi Tao, Sheng Jin, Qinyue Li, Wei Li, Chen Change Loy
- 开源代码: https://github.com/wusize/OpenUni
- 联系方式: size001@e.ntu.edu.sg
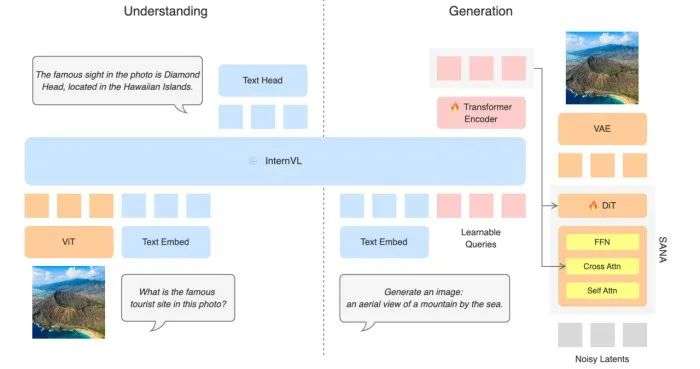
架构图,OpenUni 架构:通过 256 个可学习查询和 6 层轻量连接器,桥接冻结的 InternVL(理解)与 SANA(生成)
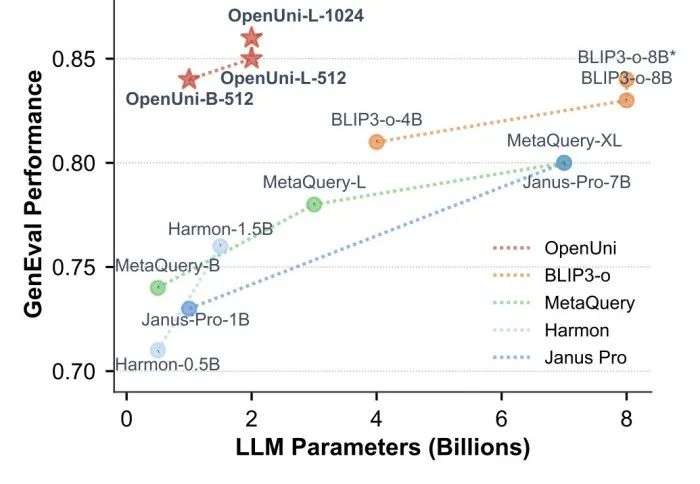
图 1:OpenUni 在生成任务上的性能表现,展示了其高效的参数利用
三大核心优势
1. 架构极简
仅 6 层连接器,相比 MetaQuery 的 24 层大幅精简
2. 参数高效
1.1B 参数达到 GenEval 0.84 分,与 BLIP3-o-8B 模型性能相当
3. 完全开源
模型权重 + 训练代码 + 2300 万数据集全部公开
架构设计与训练策略
OpenUni 遵循 MetaQuery 的设计理念,包含四个核心组件:
1.256 个可学习查询 – 从用户指令中提取条件信息
2. 冻结的 InternVL – 保持原有理解能力
3.6 层 transformer 连接器 – 基于 ViT 架构
4.SANA 扩散模型 – 高效图像生成
模型对比
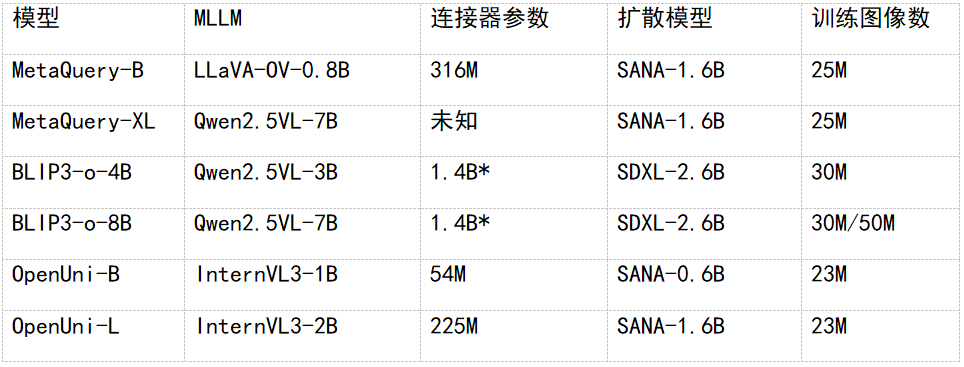
* 对于 BLIP3-o,将预测 CLIP 特征的 DiT 视为连接器
关键特点: – 连接器参数大幅减少 – 使用更小的 MLLM 和扩散模型 – 训练数据完全公开
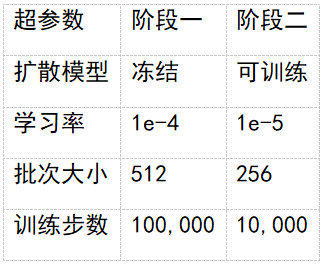
两阶段训练策略
第一阶段:预训练(2300 万图文对)
- 目标:训练可学习查询和连接器
- 策略:冻结 MLLM 和扩散模型
- 数据:公开数据集,使用 LLM/MLLM 重新标注
第二阶段:微调(6 万图文对)
- 目标:提升生成质量
- 策略:解冻扩散模型,联合优化
- 数据:BLIP3-o 贡献的高质量数据集
性能验证
OpenUni 在参数效率上表现出色:
- OpenUni-B-512:1.1B 激活参数,GenEval 达到 0.84 分,与 BLIP3-o-8B 持平
- OpenUni-L-512:3.1B 激活参数,GenEval 达到 0.85 分
- OpenUni-L-1024:3.1B 激活参数,GenEval 达到 0.86 分,为开源统一模型最佳
其他基准测试
- DPG-Bench:OpenUni-L-1024 获得 83.08 分,超越所有 MetaQuery 和 BLIP3-o 变体
- WISE:OpenUni-L 达到 0.52 分,与 BLIP3-o-8B(公开数据版)持平
生成效果展示

图 2:OpenUni-L-1024 生成的多样化高质量图像
多模态理解能力
由于采用冻结 InternVL3 的策略,OpenUni 继承了其理解能力:

图 3:OpenUni-L 的多模态理解能力展示
理解基准测试
应用前景与开源贡献
OpenUni 提供完整的开源资源:
模型权重 – 所有训练阶段的 checkpoint
训练代码 – 完整训练 pipeline
2300 万训练数据 – 包含重新生成的 caption
详细文档 – 训练配置和复现指南
研究团队指出了当前的局限:
- 生成图像中渲染文字的能力有限
- 最大模型基于 2B MLLM 和 1.6B 扩散模型,有待扩展图像到
- 图像生成任务将在未来版本支持
- GenEval 的局限性,由于 prompt 范式固定,模型经过 GPT4o 蒸馏数据(BLIP4o-60K)微调后在 GenEval 上大幅提升;作为统一模型(Show-o,Janus,Harmon,Bagel)常用的指标,GenEval 难以再真正衡量模型能力
总结
OpenUni 为统一多模态模型提供了一个简单但强大的基线。通过极简的架构设计和高效的参数利用,OpenUni 展示了:
- 更少的参数可以达到有竞争力的性能
- 简单的设计往往更有效
- 完全开源促进社区研究和创新
作为一个持续进行的项目,OpenUni 为研究社区提供了清晰、可复现、易扩展的基线实现。
文章来自于微信公众号“机器之心”。









